ODA - Parking Fines #2 - Locations
In my last post I have explored the parking fines dataset that is provided by the city of Aachen through its open data portal. While this exploration already led to some very interesting findings, I also noticed that the location information that is provided in the original dataset is not usable for a detailed analysis. In this post we will explore the available location data in more detail and try to convert the provided natural language descriptions into coordinates.
This post is a continuation of my first look at the discussed dataset. If you want to get familiar with the contents of the dataset you can find a lot of insights in my last post.
The Situation
Couvenstraße in front of library
As we have discovered in our first investigation of the parking fines dataset, creative location descriptions such as the one that can be seen above can be found in the “Tatort” (crime scene) column of the dataset. Because of this, we only focused on the street name and did not consider the locations in a more detailed manner. This however always bugged me and when the topic of this particular dataset popped up again in one of the monthly open data Aachen meetings, I set out to take a look at this situation again. So here we are!
Upon closer inspection of the location column, we see that only a fraction of the location descriptions is as creative as the prior example. In fact, most of the descriptions follow some kind of pattern including the street name and a further specifier such as a house number or a crossing with another street.

The most simple case can be seen in the image above. An exact address with streetname and house number and no additional information, e.g. Pontstraße 131. Since we know that we are located in Aachen, a post code is not necessary and the provided information is sufficient in order to specify an exact location - check! While this covers more descriptions than expected - about 43% - this is not good enough for us!
Adalbertsteinweg vor Haus-Nr. 146
The other frequent type of pattern can be seen above. The description begins with the street name, followed by a relation (e.g. in front of, opposite of, …), followed by the string Haus-Nr. (house number) and the actual number. Since the relation and fixed prefix part are almost always the same, without any spelling mistakes, I assume that the system used by the Ordnungsamt actually provides this template to the operators. This second pattern covers another 28% of the fines, bringing us up to a total of 71% - much better!
Thomashofstraße, Ecke Robensstrasse
Last but not least there is a third pattern, which is however much less frequent. In this pattern the Ecke keyword is preceeded and followed by a streetname, indicating that the fine was issued at the intersection of these two streets. This pattern can only be found in about 3% of the descriptions and will later be harder to transform into coordinates. Because of this it is not considered further in the following.

The ramaining ~30% of datapoints contain descriptions that include POI names or other specifiers such as churches, schools, or parking lots. While it may be possible to parse these in the future, they were not considered further this time because of their complexity compared with the other 70% of cases.
Geocoding
Now that we have identified the two main patterns, covering over 71% of all datapoints, we can start thinking about how these can be transformed into exact coordinates. The process of converting addresses into geo location information is called geocoding. When you type an address into Google/Apple Maps and it shows you the corresponding location on the map, their servers are performing the geocoding of the typed address for you. This is what we are essentially trying to do here. I already touched this topic in the previous post, where we tried to link the street names to their corresponding polygons in the openstreetmap data. We will be using a similar approach here.
My first idea was to simply perform a query to the openstreetmap geocoding API Nomatim which is freely available. This API is provided with a search area (in order to give it a rough context, in our case this would be Aachen) and the search string. It returns the most likely corresponding coordinates - exactly what we need! However, since the API is freely available it is (understandably) rate limited and a maximum of one request per second may be performed. Since our dataset is quite substential, containing hundres of thousands of datapoints, using this API would have meant waiting over one and a half days for only the 2020 dataset. I already faced a similar problem when previously working with the dataset, hitting the rate limits of the Apple Maps API.
This solution therefore is no solution. The good thing about openstreetmap however is, that it is open source and all of the map data can be downloaded and used offline. I made use of this in the prvious post, where I downloaded all streets of Aachen using the Overpass API of openstreetmap. In addition to the streets however, we now also need information about house numbers. So I tried downloading the needed information using the Overpass API again. This sadly failed because the request exceeded the size limit set by Overpass. This is again a limitation caused by the free nature of the API.
Searching for a different solution I stumbled upoon bbbike.org, a site which allows you to select an area of openstreetmap and download it in one of many available formats. An incredably useful service which I am very grateful for, go ahead and check it out! The site allowed me to download the complete openstreetmap data of Aachen, including information about streets and housenumbers - perfect!
Now that the question of getting the data was answered, the next challenge was the geocoder itself. The nice thing about the Nomatim API is, that it provides the data and the geocoder at the same time. Having the offline data, I can no longer make use of the geocoder part of the API. While the underlying geocoder is actually open source* and can be set up and used locally, this is quite an involved process that requires setting up a dedicated server and environment which I was not keen on doing. Gladly, I found a very old GitHub project by brianw in which he implemented a very simple geocoder for osm data. This was a great basis for my geocoder. While the outdated code caused some headache and needed to be converted to a modern version of Python, it did actually work in the end. The geocoder did not consider house numbers however - the thing that I was most interested in. After some tinkering and some adjustments to the framework provided by brianw I was able to include house numbers and the geocoder was finally working nicely. Success!
All that was left to do now, was to take the location description, split it up into its distinct parts using the identified patterns and build a well formatted address out of it. “Franzstraße ggü. Haus-Nr. 40 - 42” would for example be transformed into the search string “Franzstraße 40”. As you can see, currently some information is lost due to the different formatting of house numbers. House numbers may actually indicate ranges or contain further specifiers such as 10b. This is actually already handled by the code, but not considered further at the moment. In such special cases, the first occuring number without any specifiers is used currently. This can certainly be improved in the future!
Summary
In this post we explored the conversion of human-written descriptions of locations into machine readable coordinates. While there certainly are fines for which the exact location cannot easily be inferred, the presented approach works for a large fraction of the parking fines dataset. The exact location information enables a whole array of additional interesting analysis possibilities for the data and I will certainly explore some of these possibilities in the future.
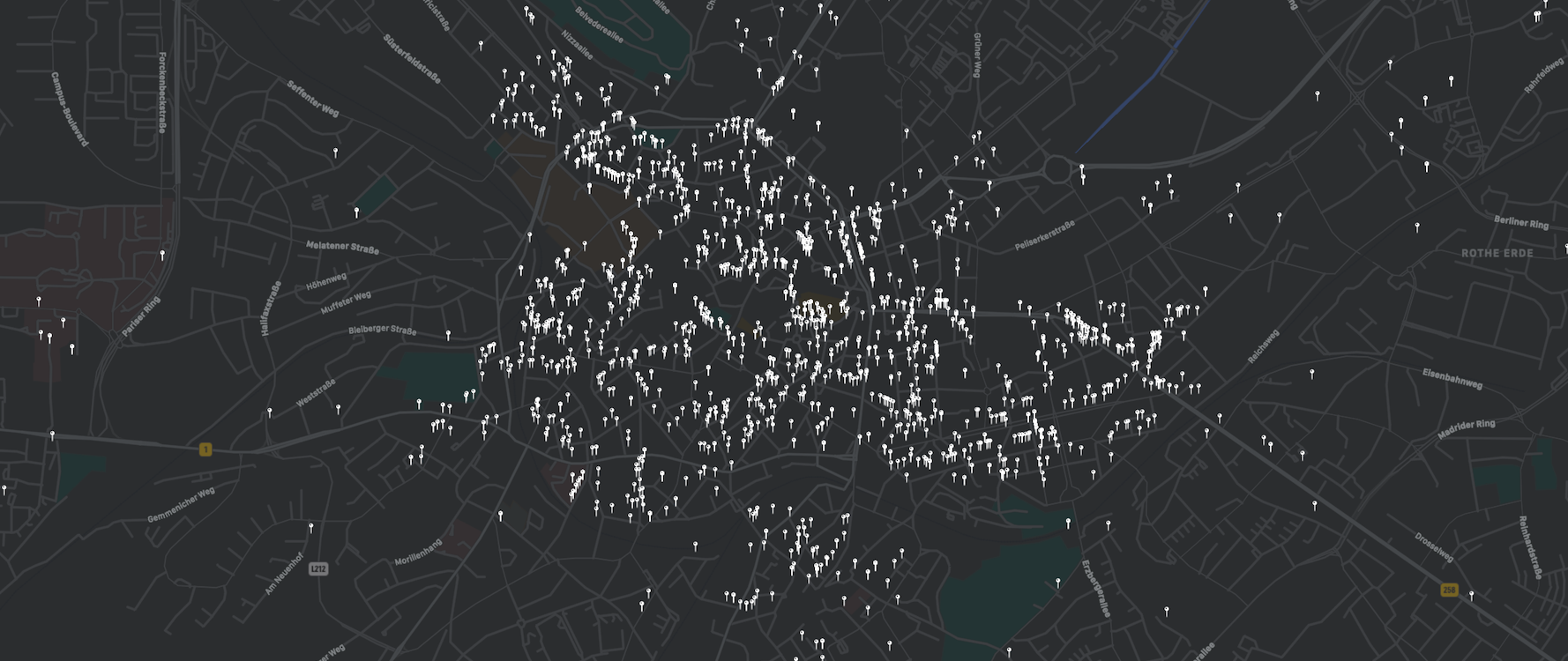
In addition to that, further improvements of the conversion approach are possible and should be considered. For example, the different relations are currently ignored. However, “next to” and “opposite of” indicate different sides of the street - information that might be important for some use-cases. A better handling of special house numbers, as described above and also parsing the third frequent pattern are other possibilities for future improvement.

For the first time the results of one of my posts are available on GitLab! Feel free to check them out! The repository also includes a combined dataset, containing both available parking fines datasets and the parsed latitude and longitude information.
* During the process I learned that the outdoor app komoot is actually using a custom version of this geocoder under the hood - interesting!
If you have any remarks or comments, join the discussion of this post on twitter.