Unscramble
For a long time online news offerings have mainly sustained themselves through advertisements on their site. In recent years, more and more of these sites, espacially those that have a backround in offline print have also started offerering some kind of premium subscription. A common practice is to mix some amount of free content with premium content that requires a premium membership. Those premium articles are then locked behind a paywall that obfuscates the content in some way. In certain cases there are ways to circumvent this obfuscation and we will take a look at one example of that in this post.
The Problem
So I must admit, I am sometimes overly interested in local news topics. For example if there is a big construction project going on in the city, I must know all about it. The best way to keep up with such projects is through the local newspaper. Of course nobody is actually buying physical newspapers anymore today, and that fact especially applies to me. But that is not actually a problem, because our local news orginization here in Aachen, the Aachener Zeitung respectively Aachener Nachrichten has a great web offering that could perfectly satisfy my needs. It is so good indeed, that it actually exists twice. Once under the name Aachener Nachrichten and once under the name Aachener Zeitung, the names are distinct, the domains are aswell but the websites and their content are exactly the same (If you don’t count the different coloring)*. I am sure there is an interesting historical reason for that, but this should not be the topic of today.
Todays topic is their premium offering. There are some articles on the site that are free** for everyone and there are even more articles that can only be accessed through a premium subscription. The design that they are using is found across many different sites. You can read the first paragraph of the article, then there is an advertisement for the premium subscription and below that there is a blurred out version of the article.

As said before, this is a common pattern across many different publications. I have experienced it before on Welt which is a large german news site. Of course these kind of implementations make you curious: How do they do this? A static image used for each article? Just overlay the text with a blur? The first step of the investigation was to simply try to select the text under the blur. This was not possible (at least not in Safari), but also showed that the blur section is not a simple image. Next step is the element inspector, the web developers best friend (Not implying that I would know anything about web development).

Digging a little in the div hierarchy we find that there is actual text behind the blur curtain! And while it looks to have a kind of word structure, the words themselves are gibberish, just sequences of random letters. I guess that the length of these fake words actually matches the real article, just that all of the letters have been replaced with random ones. A clever way to approach this problem! This result is not really surprising, I mean it would have been way too simple to just find the full text when looking at the source of the site.
Let’s take a step back again and return to the initial problem: My obsession with local news, combined with the fact that most of the articles that would be of interest to me are hidden behind the premium subscription. This subscription costs (at the time of writing) 9,99€ per month. Which I actually think is a pretty fair price for a complete access to all of the content of the newspaper. The problem for me is that I don’t need access to the whole content, for any given month there are probably 2-3 articles that would be of interest to me. 9,99€ for 3 monthly articles does not sound like such a fair price anymore. Is there a solution to this problem that would let me access the articles I really want to read and would also compensate the newspaper?
Yes there is was! In the past the site actually offered an option to access all of the articles for 24 hours, for a small fee of 1,99€. The perfect solution for me! I would pay for the 24h access once a month and would read all of the articles that interested me in that time. This way I got what I wanted and the newspaper was actually payed for their work, seems like a win-win situation to me. But it seems that the newspaper did not see this in the same way, because the option for the 24h access was removed a few months ago and was replaced with the gracious offer to get one free trial month for the premium subscription. This has now bugged me for some time, whenever there is the occasional article that I really need to read. But the only option here is to pay the 9,99€ and when I think about it, I really don’t need to read it that urgently.
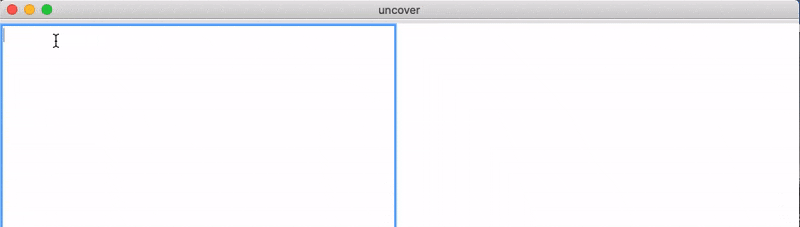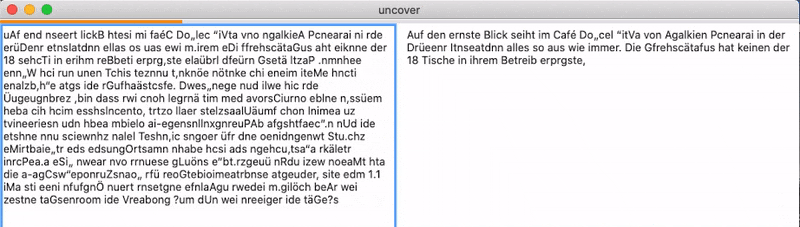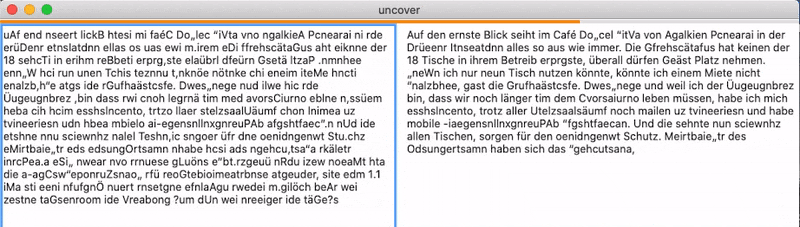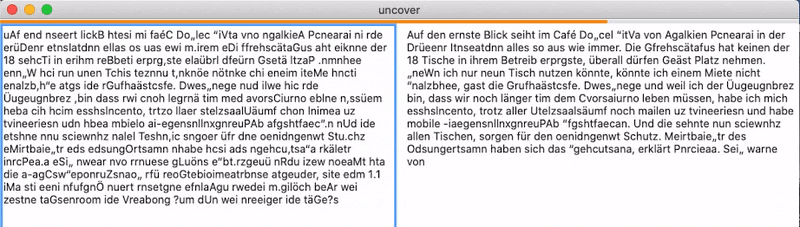
Yesterday was such a day again, I found an article that I was interested in and there was no feasible way to read it. So I remembered the Welt site and just out of curiosity took a closer look at the article. The Aachener Nachrichten site actually allows you to select the content behind the blur, so the investigation started off on an easier path than the Welt site already. Pasting the content in a text editor would reveal something like this:
saW tsi hcint sllae eürb mher sal hnez aJrhe nhi udn rhe tiskeurdit do.
The german reader might notice something here and for the non german reader I will explain: The words do not consist of random letters here, they are anagrams of real words. So this paywall is implemented in such a way, that the letters of the real words of the article are actually just scrambled! This does not allow us to get a plain text version of the article directly, but it gives us much more information than the Welt implementation. Actually, if you concentrate a little and know the context of the article, you can read it, albeit very slowly. So how to proceed from this point? Accept defeat? Or just read the interesting articles very slowly? No I had a different idea, actually inspired by my work on Morph.
In morph you try to create words by modifying other words, in order for the game to make some kind of sense I need to make sure that the player is actually creating “real” words and not just going from one string of random letters to another. So I actually created*** a system that can recognize “real” german words in the past, could it be applied here?
The Solution
Yes it could! So I invested half an afternoon in this project with the goal to “decode” the scrambled text of the site, based on my existing word checker and it kind of worked! You can see an example above. And as you can also see there, there are some problems with this naive implementation. The most important problems are:
- Some words are converted into correct words that are not fitting the context.
- It is very slow.
- Some words are not “decoded” at all.
So let’s go through them one by one and talk about some implementation details while doing so.
1.
Some words are converted into correct words that are not fitting the context.
Already the third word in the example text is wrong. Altough it is a correct german word, it does not fit in the context at all. The tool decodes the scrambled word as “ernste” meaning “serious”, the correct word here would be “ersten”, meaning “first”. These semantic mismatches are easily explained by the simplicity of the implementation. We have a word checker, that for a given string just outputs if it is a german word or not. It does not take any context into account. The tool just outputs the first string that is actually a word, therefore semantic mismatches can and will happen.
2.
It is very slow.
Altough the tool is simple in it’s idea, it is very complex regarding time complexity. We recieve a list of letters as input and want to find their correct order. Correct meaning that they are in an order that forms a german word. The naive approach here is to just try all possible permutations of the input letters and for each permutation check if it is a word. Since a list of n letters has n! permutations, we have a frightening time complexity of O(n!). This could probably be dramatically improved by using some language heuristics regarding the sequence of letters. For example there are not many words that contain the sequence kp, as it is not pronouncable, however sequences such as se or po are much more frequent. One could therefore prune permutations that contain such improbable sequences in order to improve the translation speed.
However, at this point the implementation is dumb and simply tries all of the permutations until it finds a valid word. There are some improvements that are already implemented, like always putting the capital letter at the front of the word and putting punctuation at the very end. But to be honest it is still pretty slow, altough for most articles it is actually possible to start reading while the translation is happening without ever having to stop reading, as translation is faster than reading.
3.
Some words are not “decoded” at all.
This is actually closely related to Problem 2., as we have a factorial time complexity, it is simply not feasable to decode words longer than 7 letters (5,040 iterations), as increasing the limit to 8 letters would raise the number of required iterations to 40,320, which is certainly not impossible on modern hardware, but also not suitable for the given problem. I thought about using the auto correction that is also provided by UITextChecker, by just feeding it the random letter word and letting it figure out the word. While this actually results in a real german word most of the time, the word will often be so different from the intended word, that it actually makes reading harder than just keeping the scrambled word.
Conclusion
So what’s the conclusion of this whole story? It was a fun little afternoon project, but while the results are actually improving the readability of the text, they are still far from usable. I will probably revisit this project in the future, as there are some improvements that could be made without too much effort. But let’s be honest, it will never be able to perfectly decode a whole scrambled article. Even if made somewhat context sensitive, it could never be sure about which word to choose. There are also other obvious problems, such as place names, numbers and persons which simply cannot be decoded at all. Well, let’s never say never, there may be some fancy machine learning approach, but would it be worth it? Probably not, but let’s see what the future brings.
Altough the approach did not deliver satisfying results, I would still advise the tech department of Aachener Nachrichten to maybe change to the approach taken by Welt. While at least somehow encoded, you are still putting all of your content out in the world for free in some way. And if there is someone that is motivated enough, he could circumvent your paywall. Just putting random letters in the place of your hard work could solve the “problem”. What is still not solved is my initial problem, I still cannot read the few articles that interest me without paying way too much. Maybe the 24h option will come back some day, I can only hope.
* BTW I like the yellow one more, but to each their own. At least there is some variety!
** Of course they are not free, but they are free to access, financed through advertising.
*** Created may be a strong word here, as the implementation mostly relies on the UITextChecker provided by Apple, which can be used to check if a word is spelled correclty. I just adapted it a little for the task.
If you have any remarks or comments, join the discussion of this post on twitter.